Nama Kelompok 4 :
1. Husna Aprillia Damayanti (12119852)
2. Novi Puji Lestari (14119838)
3. Reistika Pravitasari (15119415)
4. Renancy Lyna Saraswaty (15119430)
JURNAL 1
PENERAPAN DATA MINING PADA PENJUALAN MAKANAN DAN MINUMAN MENGGUNAKAN METODE ALGORITMA NAIVE BAYES
1. Type Data
|
Bulan |
Makanan |
Minuman |
|
Februari |
11373000 |
3791000 |
|
Maret |
12750000 |
4250000 |
|
April |
2550000 |
850000 |
|
Mei |
3060000 |
1020000 |
|
Juni |
15300000 |
5100000 |
|
Juli |
17850000 |
5950000 |
|
Agustus |
25500000 |
8500000 |
|
September |
38250000 |
12750000 |
|
Oktober |
22950000 |
7650000 |
|
November |
22950000 |
7650000 |
|
Desember |
22236xxx |
7412xxx |
Tahapan
ini bertujuan memilih atribut yang dianggap sebagai atribut yang berpengaruh
terhadap klasifikasi penjualan makanan dan minuman.
|
Atribut |
|
Makanan |
|
Minuman |
Selanjutnya
mendeskripsikan data tersebut yang bertujuan untuk memahami informasi lebih
lanjut mengenai atribut dari data yang akan diolah dalam pengklasifikasian
penjualan pada restoran Makan Barbeque Sepuasnya.
|
Atribut |
Jenis |
Keterangan |
|
Makanan |
Numeric |
Nominal Penjualan Makanan |
|
Minuman |
Numeric |
Nominal Penjualan Minuman |
Pada tabel dibawah ini terdapat data yang berbeda tipe data dan data tersebut tidak valid atau salah dalam penulisan.
- Tabel Data Yang Tidak Relevan

- Tabel Hasil Cleansing Data

Data yang berjenis numerik seperti makanan dan minuman harus dilakukan inisialisasi data terlebih dahulu ke dalam bentuk nominal makanan dan nominal minuman. Untuk melakukan inisialisasi dapat dilakukan dengan sebagai berikut :
- Makanan yang terjual dengan nominal lebih dari 15.000.000 diberi inisial pada atribut Keterangan Makanan “Untung”,
- Makanan yang terjual dengan nominal kurang dari atau sama dengan 15.000.000 diberi inisial pada atribut Keterangan Makanan “Rugi”.
- Minuman yang terjual dengan nominal lebih dari 5.000.000 diberi inisial pada atribut Keterangan Minuman “Untung”,
- Minuman yang terjual dengan nominal kurang dari atau sama dengan 5.000.000 diberi inisial pada atribut keterangan Minuman “Rugi”,
Berikut adalah dataset penjualan makanan
dan minuman yang telah dilakukan inisialisasi yang terdapat pada gambar dibawah
ini.
|
Bulan |
Makanan |
Keterangan Makanan |
Minuman |
Keterangan Minuman |
|
Februari |
11373000 |
Rugi |
3791000 |
Rugi |
|
Maret |
12750000 |
Rugi |
4250000 |
Rugi |
|
April |
2550000 |
Rugi |
850000 |
Rugi |
|
Mei |
3060000 |
Rugi |
1020000 |
Rugi |
|
Juni |
15300000 |
Untung |
5100000 |
Untung |
|
Juli |
17850000 |
Untung |
5950000 |
Untung |
|
Agustus |
25500000 |
Untung |
8500000 |
Untung |
|
September |
38250000 |
Untung |
12750000 |
Untung |
|
Oktober |
22950000 |
Untung |
7650000 |
Untung |
|
November |
22950000 |
Untung |
7650000 |
Untung |
|
Desember |
22236000 |
Untung |
7412000 |
Untung |
- Menghitung Jumlah Kelas
Dari
jumlah cell (data) dari masing masing kelas dibagi dengan keseluruhan cell
(data) maka akan mendapatkan probabilitas prior. Berikut perhitungan
probabilitas prior berdasarkan persamaan :
P (Keterangan
Makanan, Untung) = 7/22 = 0,318
P (Keterangan
Makanan, Rugi) = 4/22 = 0,182
P (Keterangan
Minuman, Untung) = 7 22 = 0,318
P
(Keterangan Minuman, Rugi) = 4/22 = 0,182
|
Kelas |
Sub Kelas |
Jumlah |
Probabilitas Kelas P (C) |
|
Keterangan |
Untung |
7 |
0,318 |
|
Makanan |
Rugi |
4 |
0,182 |
|
Keuntungan |
Untung |
7 |
0,318 |
|
Minuman |
Rugi |
4 |
0,182 |
|
Total 22 1,000 |
|||
- Menghitung Jumlah Kasus Dari Setiap Kelas
Untuk
mencari nilai probabilitas posterior/jumlah kasus kejadian dari setiap kelas yaitu jumlah
atribut dengan kelas “Keuntungan Makanan” dan kelas “Keuntungan Minuman”
kemudian dibagi dengan jumlah kelas yang ada.
|
Jumlah Kejadian |
||||
|
Bulan |
Keterangan Makanan |
Keterangan Minuman |
||
|
Untung |
Rugi |
Untung |
Rugi |
|
|
Februari |
0 |
1 |
0 |
1 |
|
Maret |
0 |
1 |
0 |
1 |
|
April |
0 |
1 |
0 |
1 |
|
Mei |
0 |
1 |
0 |
1 |
|
Juni |
1 |
0 |
1 |
0 |
|
Juli |
1 |
0 |
1 |
0 |
|
Agustus |
1 |
0 |
1 |
0 |
|
September |
1 |
0 |
1 |
0 |
|
Oktober |
1 |
0 |
1 |
0 |
|
November |
1 |
0 |
1 |
0 |
|
Desember |
1 |
0 |
1 |
0 |
|
Total |
11 |
11 |
||
|
Probabilitias P (F|C) |
||||
|
Bulan |
Keterangan Makanan |
Keterangan Minuman |
||
|
Untung |
Rugi |
Untung |
Rugi |
|
|
Februari |
0 |
0,09 |
0 |
0,09 |
|
Maret |
0 |
0,09 |
0 |
0,09 |
|
April |
0 |
0,09 |
0 |
0,09 |
|
Mei |
0 |
0,09 |
0 |
0,09 |
|
Juni |
0,09 |
0 |
0,09 |
0 |
|
Juli |
0,09 |
0 |
0,09 |
0 |
|
Agustus |
0,09 |
0 |
0,09 |
0 |
|
September |
0,09 |
0 |
0,09 |
0 |
|
Oktober |
0,09 |
0 |
0,09 |
0 |
|
November |
0,09 |
0 |
0,09 |
0 |
|
Desember |
0,09 |
0 |
0,09 |
0 |
|
Total |
1,000 |
1,000 |
||
- Mengalikan Semua Variabel Kelas
Perhitungan
nilai probabilitas prior dan probabilitas posterior yang telah
dilakukan akan digunakan sebagai model yang akan digunakan sebagai acuan untuk
menentukan data testing. Di bawah ini merupakan contoh data testing yang
akan di hitung probabilitasnya.
1) Untuk
semua atribut kelas Keterangan Makanan = “Untung”
P (X | Keterangan
Makanan = “Untung”) = 7/11 = 0.636
2) Untuk
semua atribut kelas Keterangan Makanan = “Rugi”
P (X | Keterangan
Makanan = “Rugi”) = 7/11 = 0,363
3) Untuk
semua atribut kelas Keterangan Minuman = “Untung”
P (X | Keterangan
Minuman = “Untung”) = 7/11 = 0.636
4) Untuk
semua atribut kelas Keterangan Minuman = “Rugi”
P (X | Keterangan
Minuman = “Rugi”) = 4/11 = 0,363
5) Perkalian
probabilitas prior dengan semua atribut Keterangan Makanan = “Untung”
P (Ci | Keterangan
Makanan = “Untung”) × P (X | Keterangan Makanan = “Untung”) = 0,318 × 0,636 =
0,202
6) Perkalian
probabilitas prior dengan semua atribut Keterangan Makanan = “Rugi”
P (Ci | Keterangan
Makanan = “Rugi”) × P (X | Keterangan Makanan = “Rugi”) = 0,182 × 0,363 = 0,066
7) Perkalian
probabilitas prior dengan semua atribut Keterangan Minuman = “Untung”
P (Ci | Keterangan
Minuman = “Untung”) × P (X | Keterangan Minuman = “Untung”) = 0,318 × 0,636 =
0,202
8) Perkalian probabilitas prior dengan semua atribut Keterangan Minuman = “Rugi”
P (Ci | Keterangan Minuman = “Rugi”) × P (X | Keterangan Minuman = “Rugi”) = 0,182 × 0,363 = 0,066
- Membandingkan Hasil dari Setiap Kelas
|
Kelas |
Probabilitas |
|
P (Keterangan Makanan | Untung) |
0,202 |
|
P
(Keterangan Makanan | Rugi) |
0,066 |
|
P
(Keterangan Minuman | Untung) |
0,202 |
|
P
(Keterangan Minuman | Rugi) |
0,066 |
Dari data testing yang sudah diuji menghasilkan kelas P (Keterangan Makanan | Untung) dan P (Keterangan Minuman | Untung) memiliki nilai probabilitas tertinggi diantara kelas lainnya, sehingga dapat diambil kesimpulan bahwa makanan dan minuman memiliki probabilitas lebih tinggi.
6. Hasil yang diperoleh
Hasil
pengujian berdasarkan Accurancy
|
Skenario |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
|
|
Accurancy |
85,92 |
88,73 |
88,03 |
87,32 |
88,38 |
87,68 |
86,9 |
88,03 |
88,3 |
Hasil
pengujian berdasarkan Precision
|
Skenario |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
|
|
Precision |
45,56 |
64,62 |
56,37 |
54,43 |
58,38 |
47,78 |
56,8 |
58,03 |
66,37 |
Hasil
pengujian berdasarkan Recall
|
Skenario |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
|
|
Recall |
45,12 |
45,72 |
43,13 |
43,52 |
41,36 |
42,78 |
44,9 |
44,83 |
48,7 |
Hasil
pengujian berdasarkan Nilai Kappa
|
Skenario |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
fold |
|
|
Kappa |
0,392 |
0,425 |
0,453 |
0,21 |
0,34 |
0,444 |
0,42 |
0,411 |
0,431 |
7. Tools yang digunakan
- Algoritma Naive Bayes
Dalam teorema Bayes, probabilitas dapat dinyatakan sebagai berikut :

Diketahui
:
X = bukti, H = hipotesis, P(H|X) adalah probabilitas bahwa hipotesis H benar untuk bukti X atau dengan kata lain P(H|X) merupakan probabilitas posterior H dengan syarat X. P(X|H) adalah probabilitas bahwa hipotesis X benar untuk bukti H atau dengan kata lain P(X|H) merupakan probabilitas posterior X dengan syarat H. P(H) adalah probabilitas prior hipotesis H, dan P(X) adalah probabilitas prior bukti X.
- Knowledge Discovery in Database (KDD)
Adalah
metode dan cara mendapatkan sebuah informasi melalui basis data yang telah
tersedia.
KESIMPULAN
- Penelitian ini dilakukan untuk mengklasifikasikan penjualan makanan dan minum pada restoran Makan Barbeque Sepuasnya menggunakan algoritma Naïve Bayes dengan metodologi KDD (Knowledge Discovery in Database). Dari hasil perhitungan klasifikasi menggunakan algoritma Naïve Bayes adalah keterangan makanan untung dan keterangan minuman untung yang lebih besar probabilitasnya.
- Hasil pengujian klasifikasi algoritma Naïve Bayes dari sembilan skenario pengujian yang telah dibuat dengan cross validation, menghasilkan performa terbaik pada skenario pengujian dengan menggunakan 3 fold yang menghasilkan performa terbaik dengan nilai accuracy sebesar 88,73%, precision sebesar 64,42%, recall sebesar 45,41% dan dengan nilai kappa yang diperoleh sebesar 0,451 yang termasuk kedalam kategori cukup. Berdasarkan hasil tersebut maka, model yang dihasilkan oleh algortima Naïve Bayes ini konsisten.
JURNAL 2
Penggunaan Data Mining dalam Kegiatan Sistem Pembelajaran Berbantuan Komputer
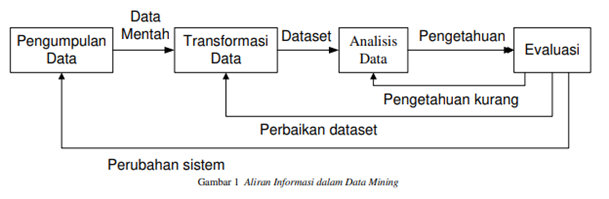
Data mining merupakan suatu langkah dalam Knowledge Discovery in Databases (KDD). Knowledge discovery sebagai suatu proses terdiri atas pembersihan data (data cleaning), integrasi data (data integration), pemilihan data (data selection), transformasi data (data transformation), data mining, evaluasi pola (pattern evaluation) dan penyajian pengetahuan (knowledge presentation). Data mining mengacu pada proses untuk menambang (mining) pengetahuan dari sekumpulan data yang sangat besar. Kerangka proses data mining tersusun atas tiga tahapan, yaitu pengumpulan data (data collection), transformasi data (data transformation), dan analisis data (data analysis).
Proses tersebut diawali dengan preprocessing yang terdiri atas pengumpulan data untuk menghasilkan data mentah (raw data) yang dibutuhkan oleh data mining, yang kemudian dilanjutkan dengan transformasi data untuk mengubah data mentah menjadi format yang dapat diproses oleh data mining, misalnya melalui filtrasi atau agregasi. Hasil transformasi data akan digunakan oleh analisis data untuk membangkitkan pengetahuan dengan menggunakan teknik seperti analisis statistik, machine learning, dan visualisasi informasi.
Sistem pembelajaran berbantuan komputer (computer aided learning system) dapat diimplementasikan sebagai sistem tutorial berbasis web (web-based tutoring tool) atau sistem tutorial cerdas (intelligent tutoring system). Dalam sistem tutorial berbasis web maupun sistem tutorial cerdas, setiap interaksi siswa dengan sistem akan dicatat dalam suatu basis data dalam bentuk web log atau model siswa (student model). Setelah sistem tersebut digunakan dalam proses pembelajaran selama jangka waktu tertentu, maka akan terkumpul sejumlah besar data. Kumpulan data tersebut dapat diproses lebih lanjut dengan data mining untuk memperoleh pola baru yang dapat digunakan untuk meningkatkan efektifitas dalam proses pembelajaran.
- Data yang digunakan:
Metode Algoritma association rule (AR)
Classification

Clustering

- Atribut


- Type Atribut
- Preprocessing
- Task Mining
- Hasil
- Tools yang digunakan
Abstrak
PT. Pangan Lestari adalah perusahaan pemasok, dalam kesehariannya memiliki permasalahan yaitu dalam memprediksi barang yang laku berdasarkan hasil penjuala. Penggunaan data mining, dalam hal ini adalah berupa Metode Naïve Bayes sangat membantu dalam prediksi berapa stok yang disiapkan dan produk apa saja yang tidak laku. Dengan adanya bantuan alat aplikasi ini diharapkan penjualan akan meningkat karena konsumen senang belanja di sini karena barang yang akan di beli selalu tersedia, jenis variannya, dan selalu baru, belum kadaluarsa.
Kata kunci:Penjualan, Metode Naive Bayes, data mining- Data yang digunakan:
Metode Algoritma Naive Bayes
Naive Bayes merupakan teknik prediksi berbasis probabilitas sederhana yang berdasarkan pada penerapan teorema bayes dengan asumsi independensi yang kuat. Dengan kata lain, dalam Naive Bayes menggunakan model fitur independen, maksud independen yang kuat pada fitur adalah bahwa data tidak berkaitan dengan data yang lain dalam kasusyang sama ataupun atribut yang lain.
Persamaan
dari Teorema Bayes adalah :

Keterangan
:
X
: Data sampel dengan calass ( label ) yang tidak di ketahui.
H
: Hipotesa bahwa X adalah data dengan class (label).
P
( H | X ) : Pobalitas H berdasarkan kondisi
X.P
(H) = Peluang dari hipotesa H.

- Preprocessing yang digunakan
Knowledge Discovery in Databases (KDD) merupakan sekumpulan proses untuk menemukan pengetahuan yang bermanfaat dari data. KDD terdiri dari serangkaian langkah perubahan, termasuk data preprocessing dan juga post processing. Data propecessing merupakan langkah untuk mengubah data mentah menjadi format yang sesuai untuk tahap analisis berikutnya. Selain itu data preprocessing juga digunakan untuk membantu dalam pengenalan atribut dan data segmen yang relevan dengan task data mining. Istilah Data mining dan Knowledge Discovery in Databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar.

Gambar 1. Proses Knowledge Discovery in Databases (KDD)
1. Data Selection
Pemilihan atau seleksi data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam knowledge data discovery dimulai. Data hasil seleksi yang akan digunakan untuk proses Data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional Sebelum proses Data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkosisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses memperkaya data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan KDD, seperti data atau informasi eksternal.
2. Transformation
Coding adalah proses tranformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
3. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam Data mining sangatbervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
4. Interpretation / Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDDyang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
- Hasil yang diperoleh
Hasil
Penelitian,sebagai berikut :
-
Perhitungan Naive Bayes
Perhitungan
Naïve Bayes dilakukan dengan menghitung menggunakan data yang diambil dari data
penjualan PT.Pangan Lestari sebanyak 3 atribut dan 300 data. Kriteria yang
digunakan adalah sebagai berikut :
-
Pengujian Naive Bayes
Pengujian pertama ini akan menggunakan satu algoritma yakni naïve baye tanpa menggunakan metode optimasi dalam melakukan klasifikasi data sebanyak 1 dataset. Berikut ini model pengujian yang digunakan dapat dilihat pada tabel …. di bawah ini :
Tabel
3. Data Customer, dan wilayah perdagangan
|
Nama Customer |
GRAN MELIA
JAKARTA, HOTEL, THE MARGO, HOTEL, SWISS BELINN KEMAYORAN, ART HOTEL, ASTON
HOTEL - ANYER BEACH, ASTON HOTEL - PLUIT – DM, ASTON HOTEL - RASUNA SAID,
ASTON IMPERIAL HOTEL – BEKASI, ASTON SENTUL LAKE RESORT & CONFERENCE,
BEST SINAR NUSANTARA, PT, BEST WESTERN HOTELKUNINGAN, FAVE CILILITAN, HOTEL,
GRAND MERCURE KEMAYORAN, HOTEL, GRANDHIKA, HOTEL, HARISTON HOTEL &
SUITES, HORISON CILEDUG, IBIS STYLE GAJAH MADA, KERATON HOTEL, NOVOTEL GOLF
RESORT & CONVENTION CENTRE HOTEL, ROYAL KUNINGAN HOTEL, POP HOTEL,
OLYMPIC PREMIER, HOTEL, THE ALANA HOTEL & CONFERENCE SENTUL CITY, THE
GROVE SUITE HOTEL, THE RITZ CARLTON HOTEL-KUNINGAN |
|
Penjual /
Wilayah |
JKT FS1H, JKT
FS2H, JKT FS3H |
|
Kode Barang |
IDT76543,
IDT78126, IDT78192, IDT78463, IDT78566, IDT78622, IDT78628, IDT78630,
IDT78632, IDT78644, IDT78651, IDT78654, IDT78655, IDT78662, IDT78688 |
|
Status |
LAKU, SEDANG,
TIDAK LAKU |
- Menghitung Probabilitas akhir setiap kelas
Menghitung probabiitas akhir pada setiap kelas, perlu menggunakan data training yang terdapat pada tabel 6 dan mengubahnya menjadi nilai yang sudah ditentukan pada perhitungan probabilitas masing- masing atribut, dari masing masing atribut dan nilai probabilitas kelas dikalikan. dari hasil yang sudah ditentukan pada tiap kelas, bandingkan nilai yang paling tinggi.jika kelas “LAKU” bernilai lebih besar maka hasilnya “LAKU”. Begitu pula dengan “SEDANG” dan “TIDAK LAKU”.-
Implementasi Klasifikasi NaïveBayes pada RapidMiner


Gambar
5. Hasil Prediksi dimana data testing menggunakan sample acak awal dan akhir
data yang digunakan dalam penelitian ini.

Gambar
6. Hasil Accuracy RapidMiner
- Tools / Aplikasi yang digunakan

RapidMiner merupakan suatu perangkat lunak yang bertujuan untuk melakukan analisis terhadap data mining, text mining dan analisis prediksi yang bersifat terbuka (open source) dan menggunakan berbagai teknik deskriptif dan prediksi dalam memberikan wawasan kepada pengguna sehingga dapat membuat keputusan yang paling baik.RapidMiner ditulis menggunakan bahasa java sehingga dapat bekerja di semua sistem operasi. RapidMiner memiliki kurang lebih 500 operator data mining, termasuk operator untuk input, output, data preprocessing dan visualisasi. RapidMiner merupakan software yang berdiri sendiri untuk analisis data sebagai mesin data mining yang dapat diintegrasikan pada produknya sendiri.
RapidMiner sebelumnya bernama YALE (Yet Another Learning Environment), dimana versi awalnya mulai dikembangkan pada tahun 2001 oleh RalfKlinkenberg, Ingo Mierswa, dan SimonFischer di Artificial Intelligence Unit dari University of Dortmund. RapidMiner didistribusikan di bawah lisensi AGPL (GNU Affero General Public License) versi 3.Hingga saat ini telah ribuan aplikasi yang dikembangkan menggunakan RapidMiner di lebih dari 40negara.RapidMiner sebagai softwareopen source untuk data mining tidak perlu diragukan lagi karena software ini sudah terkemuka didunia.
RapidMiner menempati peringkat pertama sebagai software data mining pada polling oleh KDnuggets, sebuah portal data mining pada tahun 2010-2011. RapidMiner menyediakan GUI (Graphic User Interface) untuk merancang sebuah pipeline analitis. GUI ini akan menghasilkan fileXML(Extensible Markup Language) yang mendefenisikan proses analitis keinginan pengguna untuk diterapkan ke data. File ini kemudian dibaca oleh RapidMiner untuk menjalankan analisa secara otomatis.
RapidMiner memiliki beberapa sifat sebagai berikut.
- Ditulis dengan bahasa pemegroman java sehingga dapatdijalankan di berbagai sistem operasi.
- Representasi XML internal untuk memastikan formatstandar pertukaran data.
- Bahasa scripting memungkinkan untuk eksperiman skalabesar dan otomatisasi eksperimen.
- Konsep multi-layer untuk menjamin tampilan data yangefisien dan menjamin penangan data
KESIMPULAN
Berdasarkan pada hasil penelitian yang telah dilakukan maka dapat disimpulkan :
- Penerapan Algoritma Naïve Bayes untuk memprediksi potensi penjualan berdasarkan data set penjualan deliverance pada PT.Pangan Lestari dapat membantu perusahaan dalam memprediksi potensi penjualan.
- Berdasarkan data yang diperoleh, proses Data Mining membantu dalam penerapan metode 78 Volume 9 Nomor 1 September 2018 ISSN : 2407-3903 SIGMA – Jurnal Teknologi Pelita Bangsa Naïve Bayes dalam mendapatkan informasi dari hasil prediksi pada data penjualan delifrance di PT.Pangan Lestari dijadikan Data Mining. Sehingga dengan demikian metode Naïve Bayes ini berhasil memprediksi dengan presentase keakuratan sebesar 72,00 % dengan menggunakan data sebanyak 300. 3. Dari hasil yang diperoleh data penjualan delifrance dapat mengetahui tingkat dan volume penjualan barang PT. Pangan Lestari kepada para konsumen
Implementasi Data Mining dengan Algoritma Naïve Bayes pada Penjualan Obat
Hasil yang di peroleh dari data mining : Data mining merupakan suatu langkah dalan melakukan Knowledge Discovery in Databases (KDD). Knowledge discovery sebagai suatu proses terdiri atas pembersihan data (data cleaning), integrasi (data integration), pemilihan data (data selection), transformasi data (data transformation), data mining, evaluasi pola (pattern evaluation) dan penyajian pengetahuan (knowledge presentation). Data mining mengacu pada proses untuk menambang (mining) pengetahuan dari sekumpulan data yang sangat besar untuk menghasilkan untuk menambah sebuah pengetahuan baru dari bidang tertentu.
Pada data mining terdapat 3 bagia yaitu : Assosiation, Klasifikasi dan Clustering. Assosiation memiliki definisi sebuah proses yang digunakan untuk menemukan suatu yang terdapat pada nilai atribut dari sekumpulan data yang dimiliki, sedangkan klasifikasi adalah teknik yang di lakukan untuk memprediksi class atau propeti dari setiap instance data, dan Clustering sendiri memliki makna pengelompokan data tanpa berdasarkan kelas data tertentu ke dalam kelas objek yang sama sesuai dengan topik yang diangkat.
Masalah yang harus di pecahkan pada penelitian ini adalah bagaimana menghasilkan nilai accuracy yang jauh lebih optimal untuk mengklasifikasikan prediksi Calon Nasabah potensial untuk di tawari produk lainya data set yang digunakan pada penelitian ini.
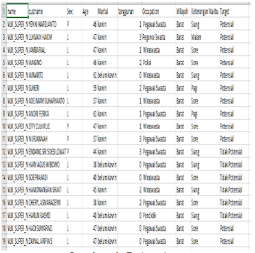
Pada gambar 1 hasil akhir dari data ini berupa kumpulan data yang sudah bersih atau tidak missing valuenya.
Pengolahan data : dataset ini dalam tahap preprocessing harus melalui 3 proses, yaitu:
- Membuang duplikasi data
- Memeriksa data yang inkonsisten
- Memperbaiki kesalahan pada data.
Data testing yang digunakan AUC digunakan untuk mengukur kinerja diskriminatif dengan memperkirakan probbalitas output yang sudah di dapatkan hasilnya dari sampel yang sudah di pilih secara acak dari populasi positif atau negative semakin besar, nilai AUC, semakin kuat klasifikasi yang dihasilkan.

Hasil dan pembahasan
Data yang
digunakan dalam pengklasifikasian Calon Nasabah potensial terdiri dari 5.000
dataset 137, yang digunakan untuk data testing
berdasarkan variabel yang tersedia. Klasifikasi dilakukan dengan menggunakan
Software Rapidminer dengan versi 8 untuk mengolah data yang sudah di tentukan.
Evaluasi dan validasi data
Validasi menggunakan 10 fold cross validation. Dimana dengan menggunakan teknik ini dengan membagi secara acak ke dalam tiap bagian dimana terdiri dari 10 bagian untuk setiap bagian akan dilakukan proses klasifikasi terlebih dahulu.
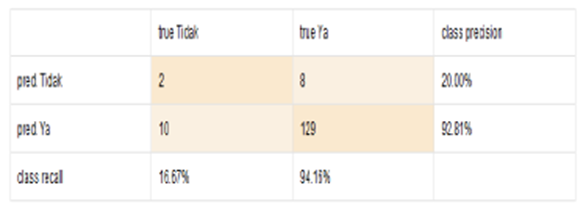

Pada gambar 4 merupakan perhitungan accuracy data menggunakan algoritma Naïve Bayes. Diketahui data training terdiri dari 150 record data, 10 data di klasifikasikan LAKU ternyata TIDAK LAKU, 2 data diprediksi TIDAK LAKU dan benar-benar TIDAK LAKU, 129 di prediksikan LAKU ternyata benar-benar LAKU serta 8 data diprediksikan TIDAK LAKU ternyta LAKU.
Dalam klasifikasi hanya terdapat satu atribut dari sekian banyaknya atribut yang bisa menjadi kemungkinan yang di sebut atribut target, sedangkan atribut lainya yang terdapat disebut atribut predictor
- Type Atribut
type ii dengan naive bayes berbasis particle swarm optimization
- Dimensi
Masalah
yang harus dipecahkan pada penelitian kali ini adalah, bagaimana menghasilkan
nilai accuracy yang jauh lebih optimal untuk mengklasifikasikan prediksi Calon
Nasabah Potensial untuk ditawari produk lainnya.

Konversi
Bahan Bakar Minyak (BBM) ke Bahan Bakar Gas (BBG) yang dilakukan pemerintah
bermula atas melimpahnya gas di bumi Indonesia. kabupaten Cilacap melakukan
survey terhadap masyarakat untuk menentukan masyarakat mana yang lebih
diprioritaskan untuk mendapatkan bantuan pemberian kompor gas beserta
tabungnya. Berdasarkan survey pada tahun 2010 di Kabupaten Cilacap Kecamatan
Kroya terdapat 17 kelurahan dengan 28.131 data dengan 31 field atau kolom. Data
diolah dengan beberapa tahapan yaitu : pengecekan data, integrasi data, target
data, preprocessing, visualisasi, proses data mining, dan pengetahuan. Pada
proses data mining dilakukan proses decision tree, regresi, dan k means untuk
clustering yang ditampilkan dalam bentuk scatter plot. Berdasarkan decision
tree maka diperoleh data kelurahan yang menjadi prioritas untuk diberi bantuan
yaitu : Kelurahan Bajing Kulon, Kedawung, Pekuncen, dan Pesanggarahan. Atribut
yang digunakan untuk proses regresi yaitu per kelurahan dengan variabel x yaitu
pendidikan atau pekerjaan dan variabel y yaitu penghasilan.
- Data yang digunakan
Tabel
1 Tabel Data Penduduk
|
Atribut |
Keterangan |
|
Kategori |
Didalamnya
mencakup data yang terdiri dari : Rumah Tangga tetap, Usaha Kecil Menengah
(UKM), Rumah Tangga Musiman |
|
Kelurahan |
Mencakup 17 macam
Kelurahan yang ada pada Kecamatan Kroya |
|
Jenis Kelamin |
Merupakan
jenis kelamin penduduk yang bersangkutan |
|
Pendidikan |
Merupakan
jenjang pendidikan akhir yang diselesaikan oleh penduduk yang bersangkutan |
|
Pekerjaan |
Jenis
pekerjaan yang dilakoni oleh setiap penduduknya |
|
Pengeluaran |
Seberapa
banyak pengeluaran yang dikeluarkan oleh setiap keluarga perbulannya |
|
Jumlah
Keluarga |
Banyaknya
jumlah anggota setiap keluarga |
|
Masak |
Dengan
menggunakan apa setiap penduduknya memasak |
|
Liter |
Jumlah liter
yang dihabiskan oleh penduduknya jika memasak dengan menggunakan kompor
minyak |
|
Rupiah |
Jumlah
pengeluaran untuk minyak tanah yang harus dibeli oleh penduduk yang memasak
dengan menggunakan kompor minyak. |
- Preprocessing yang digunakan
- ·
Mendapatkan hasil yang
lebih akurat
- ·
Pengurangan waktu
komputasi untuk large scale problem
- ·
Membuat nilai data
menjadi lebih kecil tanpa merubah informasi yang dikandungnya.
- ·
Terdapat beberapa
metode yang digunakan untuk preprocessing seperti :
a. Sampling,
menyeleksi subset representatif dari populasi data yang besar.
b. Diskretisasi,
Bagian dari data reduksi tetapi memiliki arti penting tersendiri, terutama
untuk data numerik.
c. Remove
missing
d. Continuize
e. Impute
f. Feature selection
- Hasil yang diperoleh
Penelitian yang dilakukan melalui beberapa proses yaitu :
PreProcessing
PreProcessing yang dilakukan yaitu proses pembersihan data mengalami tiga tahap pembersihan yaitu: Incomplete, Noisy dan Inconsisten. Berikut dibawah ini penjelasan dan prosesnya.
·
Incomplete Pada tahap
ini, penulis membersihkan data berdasarkan data yang tidak lengkap atau data
yang tidak terisi. Kesimpulan dari tahap ini adalah pembersihan data, dalam
artian bahwa jika attribute data tersebut kosong atau tidak terdapat nilai
didalamnya maka attribute data tersebut akan dihapus. Hal tersebut di atas
dikarenakan penulis tidak memiliki data pendukung untuk mengisi attribute data
yang kosong.
· Noisy dan Inkonsistensi Data Merupakan suatu data yang memiliki kelainan, hal ini dikarenakan karena kesalahan operator dalam memasukkan data kedalam database, permasalahan pada pentransmisian data, keterbatasan teknologi, atau tidak dilakukannya penyeragaman data, seperti data wilayah, jenis kelamin, dan lain sebagainya. Proses pembersihan data ini menggunakan suatu tools data mining yaitu Orange.
ü Pengubahan
Data menjadi Numeric
Pada langkah selanjutnya data yang sudah dibersihkan akan diubah value nya menjadi bentuk numeric, hal ini dimaksudkan agar pengolahan data pada MatLab dapat lebih mudah dan cepat, karena MatLab hanya memproses data-data numeric.
Transformasi Data
Tahapan Transformasi data adalah pengubahan format data tersimpan menjadi bentuk standar format file yang sesuai dengan aplikasi yang akan digunakan. Pada penelitian kali ini, penulis menggunakan aplikasi MatLab untuk melakukan proses data mining dengan Proses Aturan Prediksi menggunakan Regresi Linear, aturan Klasifikasi menggunakan Decision Tree. Pengubahan atau Transformasi data ke dalam format file yang sesuai adalah mengubah format file data sebelumnya yang merupakan bentuk file Tab Delimited yaitu Text atau .txt menjadi bentuk .dat.Penarikan Informasi
Berdasarkan hasil yang didapat pada 3 langkah data mining diatas, maka dapat ditarik beberapa kesimpulan atau informasi yang dapat dijadikan pengetahuan untuk diambil suatu keputusan, informasi tersebut dapat dijabarkan sebagai berikut:
- Klasifikasi dengan Pohon Keputusan/Decision Tree. Berdasarkan proses software Orange dengan menggunakan widget Classification Tree Viewer dan Classification Tree Graph bahwa keputusan yang dapat diambil oleh kepala kecamatan tentang kelurahan yang akan diberikan bantuan dengan skala prioritas adalah Kelurahan Bajing Kulon, Kedawung, Pekuncen, Pesanggarahan dan seterusnya.
- Klasifikasi dengan Regresi Linear Untuk mendapatkan informasi yang dibutuhkan dalam pengambilan keputusan dengan menggunakan Regresi Linear maka data yang ada yaitu data Pada Kecamatan Kroya dengan 17 kelurahannya harus di pecah menjadi data per kelurahan saja. Data per Kelurahan inilah nantinya akan dihitung dengan regresi linear pada Aplikasi Data Mining yang Peneliti rancang, yang kemudian hasil dari proses tersebut satu per satu Kelurahan yang ada di Kecamatan Kroya akan dibandingan secara keseluruhan. Hasil dari regresi linear ini adalah mencari nilai dari Variabel Y terkecil di kelurahan yang ada.
- Tools / Aplikasi yang digunakan
Pada penelitian kali ini, penulis
menggunakan aplikasi MatLab untuk melakukan proses data mining dengan Proses
Aturan Prediksi menggunakan Regresi Linear, aturan Klasifikasi menggunakan
Decision Tree. Pengubahan atau Transformasi data ke dalam format file yang
sesuai adalah mengubah format file data sebelumnya yang merupakan bentuk file
Tab Delimited yaitu Text atau .txt menjadi bentuk .dat.
Dapat
disimpulkan bahwa dengan menggunakan decision tree prioritas kelurahan yang
dapat diberi bantuan yaitu: Kelurahan Bajing Kulon, Kedawung, Pekuncen, dan
Pesanggarahan.
Proses
pada regresi berdasarkan per kelurahan dengan atribut untuk variabel x adalah
pekerjaan atau pendidikan dan atribut untuk variabel y adalah penghasilan.